
Snowflake customers implement several different architecture patterns with Snowflake including data lakes, data warehouses, and data meshes. To do this, customers use a mix of Snowflake features, including External Tables, Snowpipe, and Data Sharing among others. We’ve seen the impact these features have, with customers finally able to drive value from data they have been collecting for months or years.
Motivated by the simplicity of Snowflake and the rich features in the platform, we have heard from customers that they want to bring even more data to Snowflake in order to power their variety of use cases supported by data lakes and meshes. Specifically, customers want to use Snowflake innovations to solve three challenges they commonly face with large data sets: control, cost, and interoperability. As recently announced at Snowflake Summit 2022, Iceberg Tables combine unique Snowflake capabilities with the Apache Iceberg and Apache Parquet open source projects to solve these challenges and make it even easier to use Snowflake as the platform to support your architecture of choice.
What is Apache Iceberg?
Iceberg is easiest to explain with a thought experiment. Imagine you have a thousand Parquet files in a cloud storage bucket. If you have three different readers of that data, they all need to know which files correspond to a table. There could be one table that points to all of the files, or many tables pointing to a subset of the files. These users may also want to know how the table has changed over time, or optimize queries on the table. Table formats like Iceberg are designed to solve this problem—they provide rich table metadata on top of files.
While there are several table formats to choose from, we have chosen to support Iceberg because we believe Iceberg represents the best next-generation table format. Iceberg is really exciting to us because it solves some tricky problems for customers and users, including:
- Engine agnostic: Iceberg was designed from inception to be engine agnostic. This means you get rich functionality across several analytical engines, and critical functionality is not tied to only one engine.
- Diversity of thought: The Iceberg project sees active participation and contribution from many different organizations, and is not tied to any commercial entity. This means the project benefits from ideas from many different viewpoints and customer needs. Moreover, with Iceberg there’s no concern about who is controlling the project and to what ends.
- Rich ecosystem: Many different open source projects have adopted support for or extended Apache Iceberg. Moreover, commercial support for first-class Iceberg has been growing. This means customers have more capabilities and options with Iceberg.
For more detail on reasons to consider Iceberg, read this blog post. And if you are interested in Iceberg, we encourage you to check out the Iceberg Community.
What are Iceberg Tables?
Have you ever wanted a Snowflake table, with its features and performance, but also wanted the table to use open formats or your own cloud storage? Iceberg Tables are designed to meet your use case.
Iceberg Tables are a brand-new table type in Snowflake, and resemble Snowflake native tables. In fact, Iceberg Tables are designed to utilize the years of experience and innovations used for native tables. With products powered by open source, it’s common to have new capabilities that feel disjointed and separate. However, with Iceberg Tables we have tried to instead make them feel very familiar and well integrated. You can think of Iceberg Tables as Snowflake tables that use open formats and customer-supplied cloud storage.
Specifically, Iceberg Tables work like Snowflake native tables with three key differences:
- Table metadata is in Iceberg format
- Data is stored in Parquet files
- Both table metadata and data is stored in customer-supplied storage
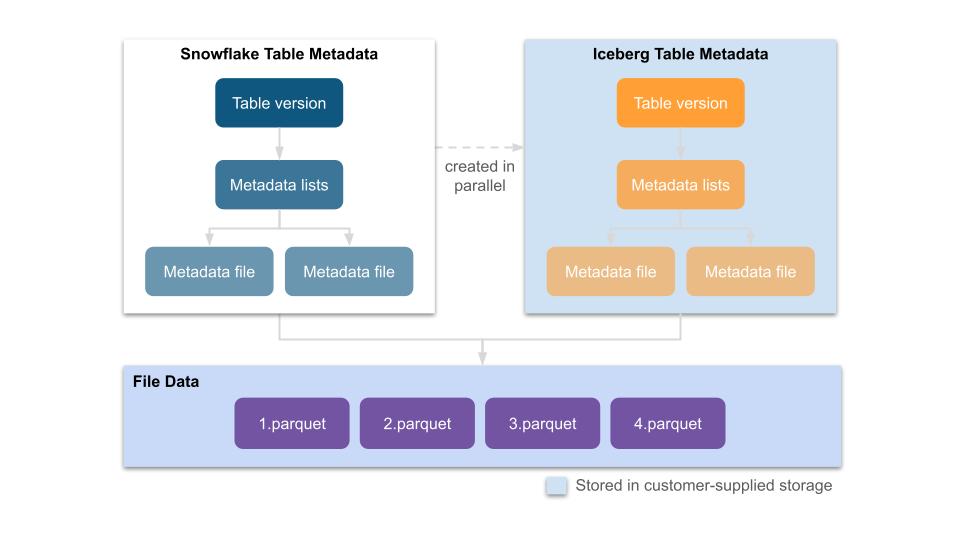
If Iceberg on Snowflake sounds familiar, it is because we launched Iceberg External Table support earlier this year. This previous launch made it possible to read Iceberg metadata as an External Table in Snowflake. Iceberg Tables, on the other hand, are much more like native Snowflake tables. In fact, we set out with three design criteria for Iceberg Tables that help explain what Iceberg Tables are.
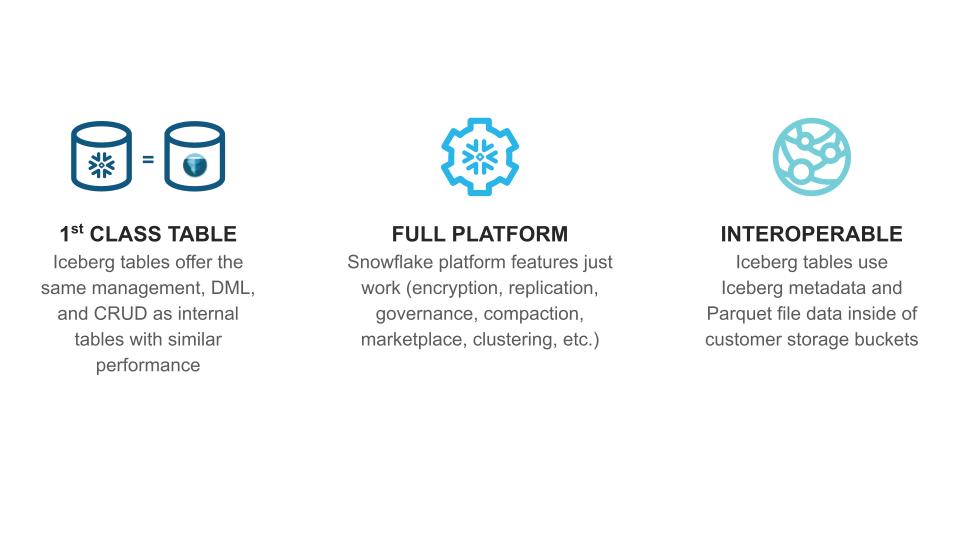
From the beginning, we designed Iceberg Tables around three important criteria: they must be a first-class table, offer full platform benefits, and remain interoperable with tools outside of Snowflake. We believe that combining the innovations powering Snowflake with open standards will unlock functionality and use cases that have previously been hard or impossible with open formats.
Iceberg Tables private preview
Iceberg Tables are now in private preview across all three clouds supported by Snowflake. With this preview, it’s possible to create both Iceberg Tables using customer-supplied storage with External Volumes, another new concept we have introduced. In this preview, you can start to get a sense for how Snowflake is bringing unique capabilities to open standards.
Creating an Iceberg Table
As mentioned, Iceberg Tables use customer-supplied storage. This means you no longer pay Snowflake for storage costs. Instead, storage is billed by your cloud provider. The first step in creating an Iceberg Table is to create an External Volume to hold the Iceberg Table data and metadata.
— Create an External Volume to hold Parquet and Iceberg data create or replace external volume my_ext_vol STORAGE_LOCATIONS = ( ( NAME = ‘my-s3-us-east-1’ STORAGE_PROVIDER = ‘S3’ STORAGE_BASE_URL = ‘s3://my-s3-bucket/data/snowflake_extvol/’ STORAGE_AWS_ROLE_ARN = ‘****’ ) );
Now you can create one or more Iceberg Tables using the External Volume. Notice there is a new iceberg table qualifier that distinguishes an Iceberg Table from a native Snowflake table. In this example, we will also pre-populate the table with data from our sales table.
— Create an Iceberg Table using my External Volume create or replace iceberg table my_iceberg_table with EXTERNAL_VOLUME = ‘my_ext_vol’ as select id, date, first_name, last_name, address, region, order_number, invoice_amount from sales;
Now you have a new Iceberg Table called my_iceberg_table, no additional work is required. You can start using this Iceberg Table like any other table in Snowflake. This means you can also do things that have been previously hard or impossible with other table formats and engines. Let’s see three examples of how this private preview of Iceberg Tables with Snowflake offers unique capabilities and can solve problems that are usually hard with open formats alone:
- Multi-table transactions
- Dynamic data masking
- Row-level security
Multi-table transactions
Some table formats cannot support multi-table transactions by design. However, with the flexibility of Iceberg and the mature Snowflake query engine, it’s easy. For example, say you wanted to delete customer data from two Iceberg Tables – sales and customers; you can do that in one transaction with Snowflake Iceberg Tables:
— Delete from two Iceberg Tables at once – sales and customers BEGIN; DELETE FROM sales WHERE last_name = ‘Smith’ and first_name = ‘Jamie’; DELETE FROM customers WHERE last_name = ‘Smith’ and first_name = ‘Jamie’; COMMIT;
Row- and column-level security
Implementing row- and column-level security can be challenging, even more so with open formats. Dynamic Data Masking for column-level security is another example of a Snowflake capability that’s easy to do out of the box with our private preview of Iceberg Tables. You can define a masking policy and then apply it to Iceberg Tables. In this example, we can mask the address field from the table we created earlier.
— Create a masking policy to mask address create or replace masking policy address_mask as (val string) returns string -> case when current_role() in (‘DBA_ADMIN_ROLE’) then val else ‘**HIDDEN**’ end; alter table if exists my_iceberg_table modify column ADDRESS set masking policy address_mask;
Similarly, applying Row Access Policies for row-level security can easily be defined and applied to Iceberg Tables out of the box—no need to tie together different open source or cloud products.
— Create a row access policy to restrict access create or replace row access policy rap_sales_manager_regions as (val string) returns boolean -> ‘sales_executive_role’ = current_role() or exists ( select 1 from salesmanagerregions where sales_manager = current_role() and region = sales_region ) ; alter table if exists my_iceberg_table add row access policy rap_sales_manager_regions on (region);
Iceberg Tables use cases
Two common questions from customers have been When should I use an Iceberg Table versus a Snowflake native table, and How do Iceberg Tables relate to External Tables? In the long-term, we are focused on developing all three table types for analytical use cases because they solve for different needs, as we also covered in this blog post announcing private preview of External Tables for on-premises storage.
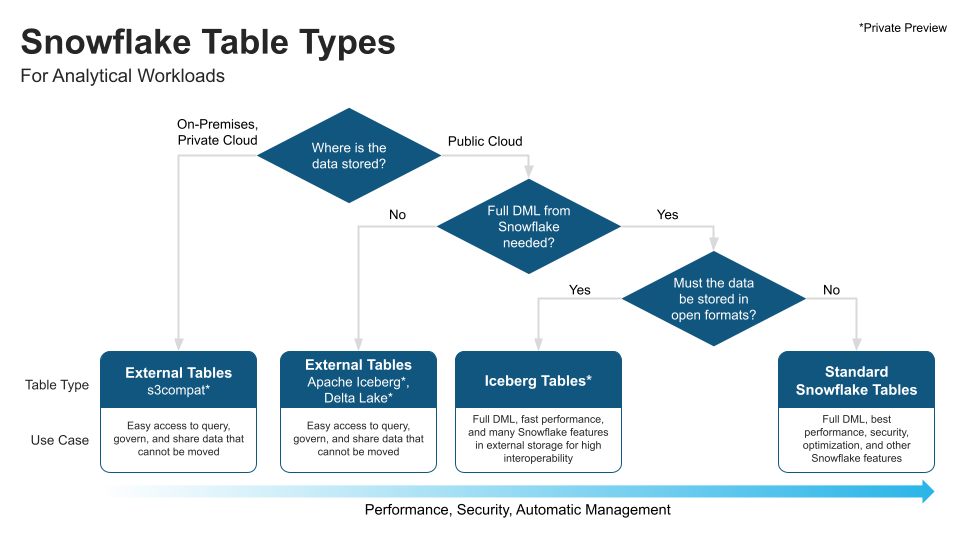
With Iceberg Tables, our goal is to get as close to Snowflake native tables as possible, without breaking open source compatibility. We believe it is important to provide customers options and to make it very clear what is open and what is not. For many customers, Iceberg Tables will complement standard Snowflake tables and External Tables. In fact, you can use the private preview to see how easy it is to work with Snowflake standard tables and Iceberg Tables, even together in one database or a single query.

Iceberg Tables are designed to address the three challenges mentioned at the start: control, cost, and interoperability.
- Control: Instead of using Snowflake formats, Iceberg Tables use open table and file formats and store data in customer-supplied storage.
- Low cost: Iceberg Tables use customer-supplied storage. So if you have been copying data between systems, you can now work with one single set of data managed by Snowflake, stored and billed separately.
- Ecosystem: Tools that know how to work with Iceberg and Parquet will work with Iceberg Tables, while Snowflake can provide a single pane of glass for security, management, maintenance, and a variety of workloads such as collaboration, data science, and applications.
Private preview and beyond
This private preview of Iceberg Tables is just the beginning. Over the course of the next several quarters, we are planning on adding new capabilities to further extend the power and flexibility of Iceberg Tables, including an easy-to-use table import and an Iceberg Metastore. Some Snowflake features will also be enabled in future releases, such as table encryption and table replication.
If you are interested in Iceberg Tables, we encourage you to test out this private preview. We anticipate you will be delighted with the flexibility, utility, and performance of Iceberg Tables. Our product and engineering teams look forward to customer feedback and use cases supported by Iceberg Tables.
Sign up for private preview
If you’re interested in trying Iceberg Tables in Snowflake, sign up for the private preview that’s now available by contacting your Snowflake account representative.
To read more about the Iceberg Tables, check out these new resources:
Originally posted on August 30, 2022 @ 9:08 am
{kind=link}