
Snowpark is the set of libraries and runtimes that enables data engineers, data scientists and developers to build data engineering pipelines, ML workflows, and data applications in Python, Java, and Scala. Functions or procedures written by users in these languages are executed inside of Snowpark’s secure sandbox environment, which runs on the warehouse. As part of running these workloads, customers sometimes require the ability to reach external network locations on the public internet outside of Snowflake. For example, data enrichment scenarios could require connecting to the Google Maps API, where users can fetch specific coordinates for an address to optimize transportation routing. And with the advancement of large language models (LLMs), customers may want to call an external LLM (such as Amazon Bedrock and Azure OpenAI) from Snowflake.
We are excited to announce the public preview of External Access, which enables customers to reach external endpoints from Snowpark seamlessly and securely. With this announcement, External Access is in public preview on Amazon Web Services (AWS) regions. Users can now easily connect to external network locations from their Snowpark code (UDFs/UDTFs and Stored Procedures) while maintaining high security and governance over their data. Partners and customers, like Airbyte and Snowflake’s internal data engineering team, are already benefiting from External Access in their workflows.
“Airbyte enables customers to continuously load data from external APIs and databases into Snowflake. External Access through Snowpark is the magic wand that enables us to run this functionality natively inside customers’ Snowflake environment. This provides Snowflake customers the power and flexibility of Airbyte’s 350+ connectors within Snowflake’s convenience and security posture.”
Sherif Nada, Founding Member & Engineering Manager, Airbyte
“External Access in Snowpark is one of the most awaited features for our internal data engineering team at Snowflake. Snowpark External Access is leveraged to build a Ingest and Reverse ETL data pipeline for production workload. This has eliminated any additional cost or dependency on external orchestrators. We minimize the number of moving pieces and don’t have to manage any additional infrastructure”
Satya Kota, Sr Manager, Data Engineering at Snowflake

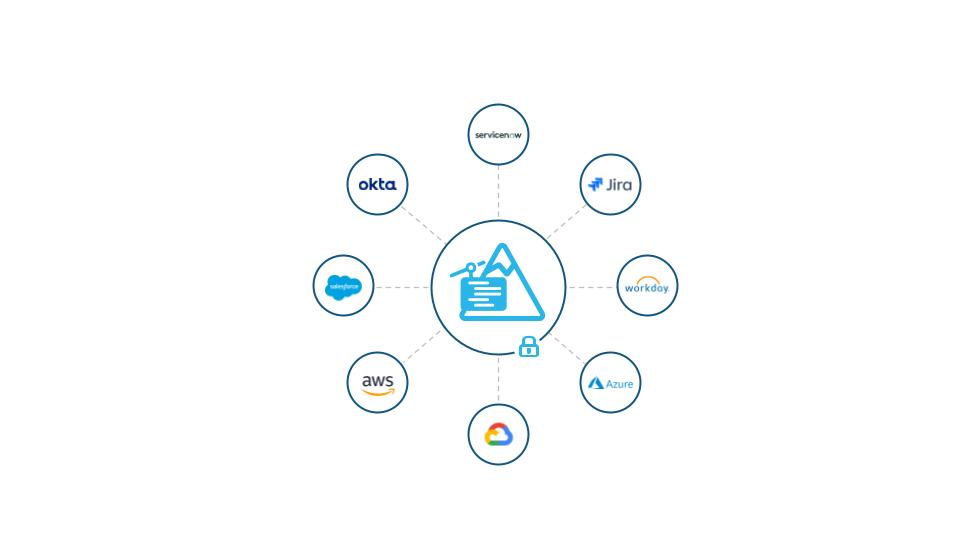
Why External Access?
For security reasons, the user’s code in the Snowpark sandbox is locked by default from accessing the public internet. Today, External Functions provide all data users a way to connect outside of Snowflake but it requires setting up additional components, such as a proxy and a remote service to run the user’s code.
External Access provides flexibility to reach public internet endpoints from Snowpark without any additional infrastructure setup. The user’s code calling an external service or API can run directly within the Snowpark sandbox. As such, this means Snowpark user-defined functions (UDFs/UDTFs or vectorized UDFs) and stored procedures can now call external network locations based on the egress network rules containing a list of trusted IP or host URLs determined by the customer. Unlike External Functions, there are no restrictions in terms of data format for data transfer. For all External Access use cases, the user has full flexibility to define the batch size, manage retry behavior or manage exception handling using UD(T)Fs or vectorized UD(T)Fs.
Beyond warehouse compute usage and egress charges as part of data transfer costs, there are no additional charges to using External Access.
Use cases
Generative AI and LLM Services: The recent surge in Generative AI, such as text generation from GPT-4, image generation from Stable Diffusion, video, audio or even code generation, summarizing data-heavy information, and others, are paving a path to revolutionize productivity in various sectors. Snowflake is building LLMs directly into the platform to help customers boost productivity and unlock new insights from their data. Outside of accessing leading LLMs with Snowpark Container Services (private preview), customers can also directly call web-hosted LLM APIs using External Access to work with Generative AI. This includes LLMs available through services such as Amazon Bedrock, a fully managed service from AWS that makes foundation models from Amazon and leading AI companies available via API, and Azure OpenAI, with an example below. To access Amazon Bedrock, one can use the short-lived AWS STS credentials to authenticate and access the Amazon Bedrock endpoints.
Data enrichment: Data engineering pipelines that require access to various public APIs for different lines of business use cases. For example, Maps API can be used to get location data, which can optimize supply chain routes. Similarly, customers also have their own API endpoints running outside of Snowflake that need to be accessed.
Ingest data from various systems: Customers looking to ingest data from sources, such as Twitter, Google Sheets, MySQL or other data sources available on the public internet, can use External Access. Snowflake already supports connectors for different data sources and External Access enables customers to ingest data from additional sources as well.
Connect to external tooling for ML: For machine learning use cases that require connecting to external endpoints to get ML artifacts, such as model artifacts data, or leverage an external MLFlow server with Snowpark, they can do so easily with External Access.
Reverse ETL: Enables copying data from Snowflake to operational systems and SaaS tools, such as Slack, so that business teams can leverage data to personalize customer experiences or drive actions. Omnata uses External Access for this scenario:
“External Access in Snowpark unlocks an enormous number of use cases for developers on the Snowflake Data Cloud, and is central to the functionality of our Native Application, Omnata Sync. Snowflake has simplified the process of connecting to external systems while maintaining the trusted perimeter that their customers rely upon.
By leveraging External Access with Snowpark, Omnata have launched the first fully native data integration product built on Snowflake which supports syncing data both to and from external Software-As-a-Service applications. Our customers have the convenience of running their data integration workloads from within their own Snowflake account, and they have full visibility and control of which external systems our native application is allowed to sync data with.” – James Weakley, Co-Founder, Omnata Co-founder
Partner Integrations: Partners can leverage External Access to connect to solutions that run outside of Snowflake. This enables seamless integration and connectivity while ensuring a scalable and secure end-to-end solution for partners like ALTR:
“With the ability to reach out to external endpoints from Snowpark seamlessly and securely, customers can leverage ALTR’s solutions while maintaining unparalleled security, flexibility, and exceptional performance.This feature complements ALTR’s scalable and highly available SaaS-based data access governance and tokenization solutions that deploy effortlessly into any environment, including the most demanding customers on the Snowflake platform.” – Christopher Struttmann, Founder, CTO | ALTR
Maintaining Snowpark’s security and governance with External Access
External Access allows the user’s code running in the Snowpark sandbox to connect to endpoints outside of Snowflake, while maintaining high security and governance. The customer’s ACCOUNTADMIN role is responsible for defining and limiting access to external network locations from UDFs or stored procedures.
To do this, the ACCOUNTADMIN or SYSADMIN needs to create egress network rules containing a list of trusted IP addresses or host URLs. Customers can leverage Snowflake’s Secret objects to store credentials in an encrypted manner within Snowflake. The secret objects are used to authenticate against the external endpoints. The account admin can then bind the network rule and secrets with an external access integration object to ensure that users can only use the specific secret for a network location with role-based access controls in place. If a UDF or stored procedure tries to reach an endpoint which is not part of the network rule or the owner doesn’t have permission, then that external access will be blocked.
To learn more about security and governance while using External Access, refer to the product documentation.
How to connect to external network locations
In this example, we will walk through how to connect to Open AI from a Python UDF.
1. Create a network rule to define the external network locations.
CREATE OR REPLACE NETWORK RULE CHATGPT_NETWORK_RULE MODE = EGRESS TYPE = HOST_PORT VALUE_LIST = (‘API.OPENAI.COM’);
2. Create a secret to store credentials. In this case, the API key is stored in the secret object ‘chatgpt_api_key.
CREATE OR REPLACE SECRET CHATGPT_API_KEY TYPE = GENERIC_STRING SECRET_STRING=’MY-KEY’;
3. Create an external access integration object that binds the network rule and secrets so that the secret can only be used with the specific network location.
CREATE OR REPLACE EXTERNAL ACCESS INTEGRATION OPENAI_INTEGRATION ALLOWED_NETWORK_RULES = (CHATGPT_NETWORK_RULE) ALLOWED_AUTHENTICATION_SECRETS = (CHATGPT_API_KEY) ENABLED=TRUE;
4. Grant usage privilege on the integration and READ privilege on the secret to the UDF developers role so they can use it.
CREATE OR REPLACE ROLE developer; GRANT USAGE ON INTEGRATION OPENAI_INTEGRATION TO ROLE developer; GRANT READ ON SECRET CHATGPT_API_KEY TO ROLE developer;
5. Users with a developer role can now create the UDF to call the Open AI API. Create the UDF with the EXTERNAL_ACCESS_INTEGRATIONS parameter set to the above create integration object. Also, set the SECRET parameter to the name of a secret included in the integration.
CREATE OR REPLACE FUNCTION CHATGPT(QUESTION STRING) returns string language python runtime_version=3.8 handler = ‘ask_chatGPT’ external_access_integrations=(OPENAI_INTEGRATION) packages = (‘requests’,’openai’) SECRETS = ( ‘cred’ = chatgpt_api_key ) as $$ import _snowflake import openai session = requests.Session() def ask_chatGPT(question): api_key = _snowflake.get_generic_secret_string(‘cred’) messages = [{“role”: “user”, “content”: question}] model=”gpt-3.5-turbo” openai.api_key = api_key response = openai.ChatCompletion.create(model=model, messages=messages,temperature=0,) return response.choices[0].message[“content”] $$;
6. Now users with USAGE privilege on the CHATGPT function can call this UDF.
select chatGPT(’Create a SQL statement to find all the stores that have more than 100 customers per day in Washington’);
How to get started
You can get started with unstructured data processing by following usage instructions in our documentation and quickstart guide, which includes step-by-step setup instructions.
We’re continuously looking for ways to improve, so if you have any questions or feedback about the product, make sure to let us know in the Snowflake Forums.
