AWS researchers are working on developing a large language model-based debugger for databases in an effort to help enterprises solve performance issues in such systems.
Dubbed Panda, the new debugging framework has been designed to work in a manner that is similar to a database engineer (DBE), the company wrote in a blog post, adding that troubleshooting performance issues in a database can be “notoriously hard.”
Unlike database administrators, who are tasked with managing multiple databases, database engineers are tasked with designing, developing, and maintaining databases.
Panda, effectively, is a framework that provides context grounding to pre-trained LLMs in order to generate more “useful” and “in-context” troubleshooting recommendations, the researchers explained.
Panda’s components and architecture
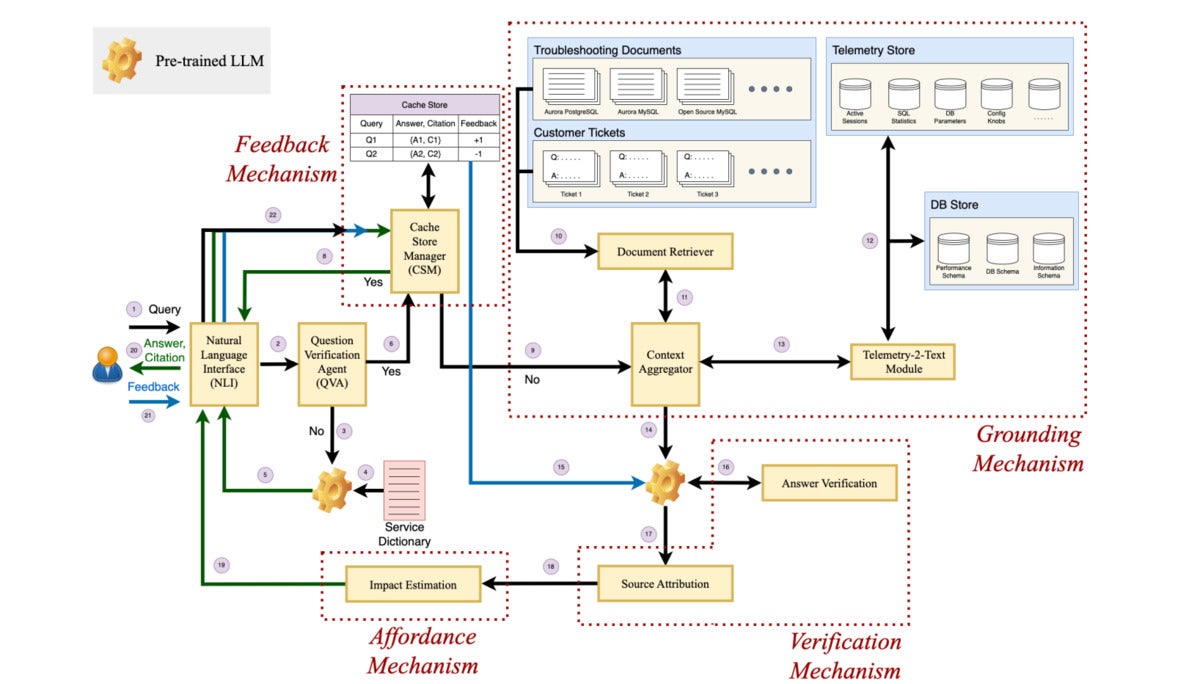
The framework includes four key components, grounding, verification, affordance, and feedback.
Researchers describe verification as the ability of the model to be able to verify the generated answer using relevant sources and produce the citation along with its output so the end user can verify it.
On the other hand, affordance can be described as the ability of the framework to inform the user about the consequences of the recommended action suggested by an LLM while explicitly highlighting high-risk action, such as DROP or DELETE, the researchers said.
Panda’s feedback component, according to the researchers, allows the LLM-based debugger to accept feedback from the user and account for those when generating responses.
These four components in turn make up the debugger’s architecture, which includes the question verification agent (QVA), the grounding mechanism, the verification mechanism, the feedback mechanism, and the affordance mechanism.
While the QVA identifies and filters out the irrelevant queries, the grounding mechanism comprises a document retriever, Telemetry-2-text, and a context aggregator to provide more context to a prompt or query.
The verification mechanism comprises the answer verification and source attribution, the researchers said, adding that all these mechanisms along with the feedback and affordance mechanism work in the background of a natural language (NL) interface which the enterprise user interacts with.
Pitching Panda against OpenAI’s GPT-4
Researchers working at AWS also pitched Panda against OpenAI’s GPT-4 model, which currently underlines ChatGPT.
“…prompting ChatGPT with database performance queries often results in ‘technically correct’ but highly ‘vague’ or ‘generic’ recommendations typically rendered useless and untrustworthy by experienced database engineers (DBEs),” the researchers wrote while showcasing a result while troubleshooting an Aurora PostgreSQL database.
For the experiment, AWS researchers had gathered a group of DBEs with three different competency levels and most of them sided in favor of Panda, the paper showed.
In addition, researchers claimed that Panda, although used on cloud databases in their experiment, can be extended to any database system.
Copyright © 2024 IDG Communications, Inc.
